Retiring my old status pages...
Even good solutions need to be quietly retired, occasionally at short notice.


Were you a good boy? You were the best.
Edit 28 April: Amazon announces they're dropping support for NodeJS 10 in AWS Lambda, so it's definitely time to change.
For the uninitiated, I'm not one for using hosted services much - never signed up at Wordpress or Medium or even Ghost.com (despite being impressed with it I switched blogging platforms).
Gmail or Office365 for email? HERESY! Hosted monitoring? Nah, rolled my own (everything from Nagios to Prometheus). Even did my own DNS and messaging for years (I think my old PowerDNS blog post still gets hits, but I can't say I've checked...)
Nope, aside from leveraging a goodly amount of Amazon Web Services because it's expensive to run kit from home like the old days, and running in and out freezing old datacentres because it'd crashed and needed the reset button pushed is so terribly quaint
(Good old qbert.thatfleminggent.com though, it had been in tucked into several loungerooms and at least two datacentres. It was a life well lived)
So all of it got virtualised. Though the hardware is gone, my penchant for over-engineering solutions lives on. I don't know what led to me running up a full Prometheus+Grafana+AlertManager stack and a mess of alerts in CloudWatch for four servers and a couple of databases, but it's there.
And because there's no point in spending that much time not to show it off and keep the users - not just me now, I've got my partner's horse breeding and agistment business to host among other bits - happy and appraised of any maintenance.
So status.thatfleminggent.cloud is a thing, a status page (think statuspage.io) that wasn't as fancy as the aforementioned Atlassian effort, but a lot cheaper.
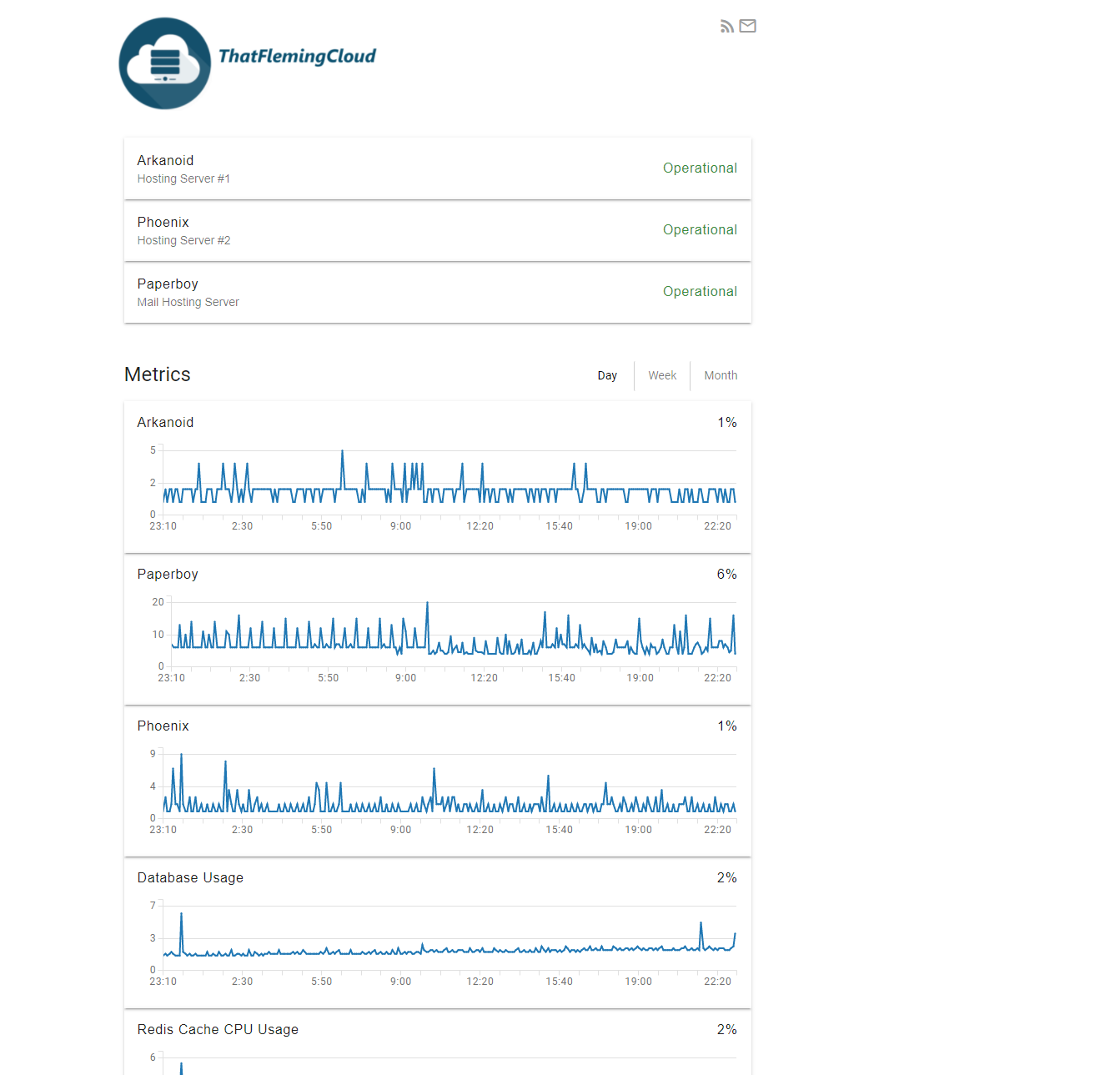
Lambstatus was my jam. It was essentially a mashup of CloudFront, AWS Lambda functions, some Cognito for authentication and SES to spam subscribers whenever I did some maintenance.
It had bugs - email time was in US Pacific, some metrics that weren't entirely useful (either pulled out of Cloudwatch or roll your own), integrations? Nope, you rolled your own hooks and liked it.
I didn't, so in order to get actual service response info I signed up for Uptime Robot, which gave me what I needed - including the ability to point a hostname at it for something a little prettier, check HTTPS, and sent whoopsies to OpsGenie and make my phone deafen me with notifications. Oh and it was free.
(I never said I used no SaaS / PaaS software, just stuff I can't / don't feel like doing myself. Plus keeping it outside my infra ensures a degree of accuracy)
But a surprise email changed that - they're removing the "custom url" and some HTTPS checks from early May unless you sign up for Pro plans.
A look at the Pro plan - still inexpensive - showed that not only can I do all the above (and 1min checking intervals and SSL expiry, which I don't really need but that's still nice) PLUS .... incident reporting and maintenance alerts.
Which got me thinking: If I fork over the lunch money for the plan, do I need my Lambstatus install? I can actually report outages automagically (via OpsGenie) and add incidents etc without hassle (there's a mobile app too)
So, given that the Lambstatus codebase is ageing (it's NodeJS 10 - was 6 until AWS dropped support) and the maintainer has archived the github repo - I'm retiring the old chap come May 5th.
I'll repoint status.thatfleminggent.cloud around then and give the old boy a well earned rest. It's been part of my reporting and visibility stack since I moved all my crap from ServersAus in 2019-ish and it's had a long life.
The only downside is that I can't save off the old and occasionally comical maintenance / incident reports (and the multiple times I've announced completed work while still leaving them open...)
And before anyone asks, yes I could self-host something like Cachet or Statping, but that means running another server (or container) which would probably cost as much, and I'd still need to maintain it and ensure it lives in another region or availability zone (because sometimes they do shit themselves)
Yeah nah, I'll let someone else do that, especially when they've got better coverage than I do :D
Though I'm still sorely tempted to run up a Sensu install...
.... I did say I over-engineer my monitoring, after all